MLOps is one of those terms that became popular faster than it became precise.
Depending on who is speaking, it can mean model deployment, ML platform work, pipeline automation, or simply “the stuff that has to happen after the notebook”. That is exactly why teams keep talking past each other. They use the same word, but describe different parts of the same problem.
Why the term gets blurry so quickly
There is a simple reason for the confusion: machine learning projects do not end with training, but training is still the part most people focus on.
When the model starts producing promising results, a new set of questions appears:
- how do we reproduce the training process
- how do we version data, code and model artifacts together
- how do we deploy changes safely
- how do we know the model is still useful after release
- who owns the system when something starts drifting or failing
Those questions are operational, not experimental. And they are exactly where MLOps starts to matter.
The most common definition is too narrow
The popular short version usually sounds like this: MLOps is about deploying and maintaining machine learning models in production.
That definition is not entirely wrong. It is just incomplete.
If we stop there, MLOps becomes a deployment label. It suggests that the real work happens during modeling, and then some separate operational function takes care of “production”. In practice, that framing is too small for what teams actually need to manage.
A more useful definition
The better way to describe MLOps is this:
MLOps is the discipline of building and maintaining a machine learning project across its full operational lifecycle.
That wording matters.
It shifts the focus away from one isolated step such as deployment. It also makes room for the parts that repeatedly decide whether the project is maintainable:
- reproducibility
- continuity
- collaboration
- evaluation
These are not optional refinements. They are the conditions under which ML work stops being a promising experiment and starts becoming an operable system.
Why MLOps is not just DevOps with a new label
This is the second source of confusion.
If we treat a model as just another software artifact, it is fair to ask whether MLOps is only DevOps with extra branding. The question is valid, because a large part of MLOps really does rely on familiar engineering foundations:
- version control
- CI/CD
- environment consistency
- artifact management
- observability
- access control
- rollback paths
So yes, a lot of MLOps looks like software engineering, because it is software engineering.
But machine learning adds a layer that classic DevOps does not have to carry in the same way:
- data quality directly affects system behavior
- model performance can degrade without code changes
- experimentation is a first-class part of delivery
- evaluation is tied not only to code correctness, but also to statistical behavior
- retraining and release decisions may depend on new data rather than new code
That is why MLOps is not a fake discipline. It is an extension of good engineering practices into a system where data, models and operational feedback loops all matter at the same time.
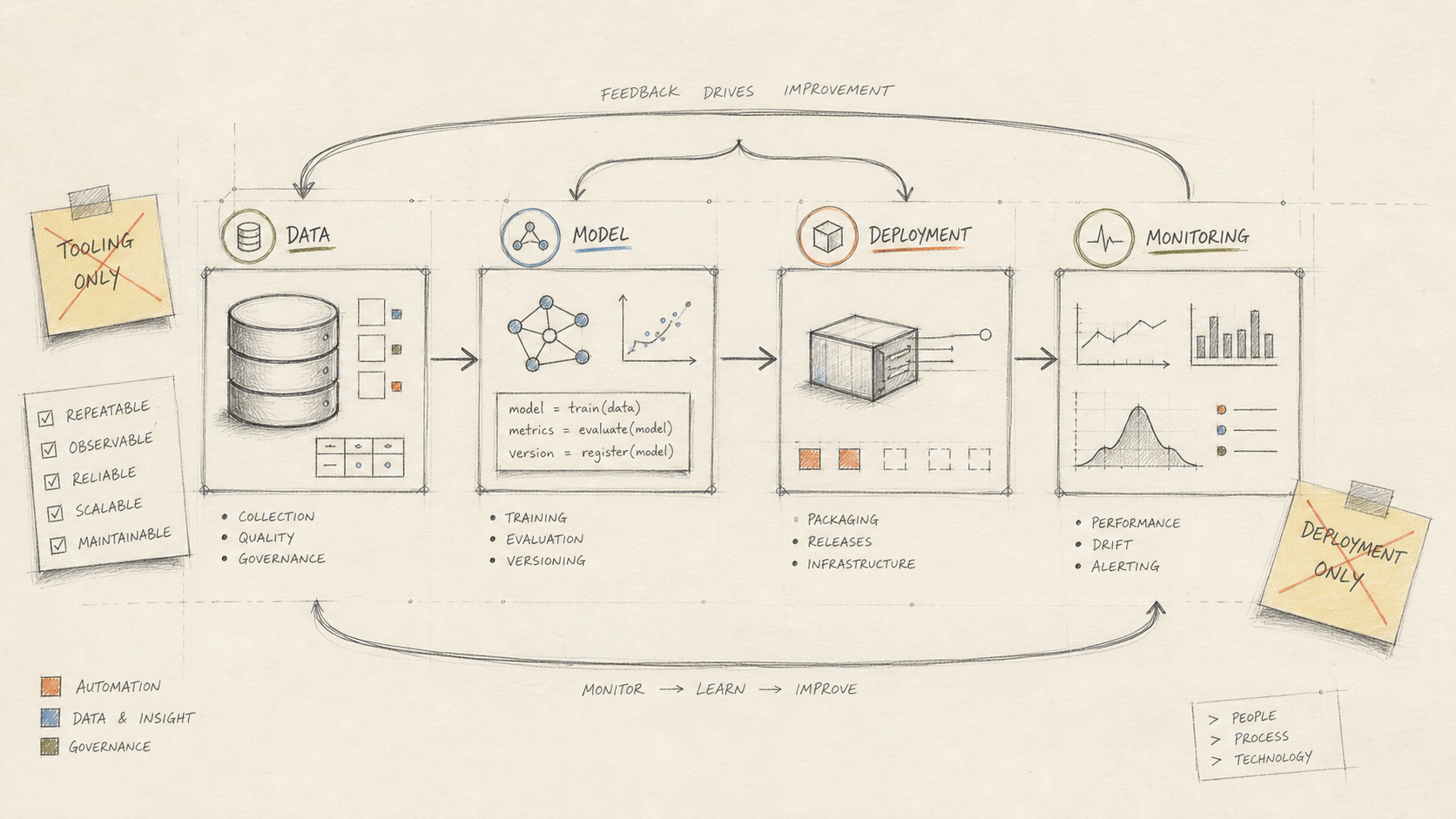
The lifecycle is the real center of gravity
The cleanest way to understand MLOps is to stop looking at a single deployment step and instead look at the whole lifecycle.
In practice, most ML projects move through four broad phases:
- Scoping: understanding the use case, constraints, risks and data availability.
- Data preparation: building the path from source data to training-ready inputs.
- Model creation: running experiments, comparing approaches and selecting a candidate.
- Deployment and operation: serving, monitoring, updating and maintaining the solution.
The important part is not just the existence of these phases. It is the fact that they form a cycle.
Data changes. Requirements shift. Model behavior drifts. Infrastructure evolves. Teams rotate. Good ML systems are not delivered once. They are revisited, corrected, retrained and upgraded over time.
That is why MLOps should be understood as lifecycle management, not as a final deployment activity.
The four principles that make the term useful
If the word MLOps is going to stay, it should point to something concrete. For me, the most useful breakdown is still a small set of principles rather than a shopping list of tools.
Reproducibility
Every important part of the system should be reproducible: code, data inputs, experiment context, model artifacts and release decisions.
Without that, teams lose the ability to debug, compare, recover and improve the system with confidence.
Continuity
ML systems live in moving environments. Data sources change, libraries age, business expectations evolve, and models need refresh cycles.
MLOps should support that ongoing movement instead of pretending that the first deployment is the final state.
Collaboration
Machine learning projects are usually multidisciplinary. Data scientists, ML engineers, data engineers, software engineers and domain experts do not work from the same assumptions by default.
MLOps should reduce friction between them by making workflows, ownership and artifacts easier to understand and share.
Evaluation
Everything should be evaluated, not only the model.
That includes:
- data quality
- training outcomes
- release readiness
- live behavior after deployment
- operational health of the surrounding platform
This is where many teams fail. They evaluate the model once, but do not build a habit of evaluating the system continuously.
Why automation is not the first question
Automation is often treated as the defining signal of MLOps maturity. I think that is backwards.
Automation matters, but only after the workflow is standardized enough to deserve it.
If a small team is still exploring the use case, rapidly changing data assumptions and iterating on problem framing, building full automation around every step can be premature. At that stage, the higher-value work is often:
- agreeing on naming and versioning conventions
- keeping experiments traceable
- defining what counts as a release candidate
- documenting the handoff between model work and production work
Only then does automation start compounding instead of amplifying chaos.
What teams usually get wrong
The recurring mistake is not that teams ignore MLOps entirely. It is that they reduce it to one visible layer.
They might equate it with:
- an orchestrator
- a model registry
- one cloud service
- CI/CD for notebooks
- deployment scripts for models
All of those can be part of the picture. None of them are the whole picture.
Once the term is reduced to tooling, teams start asking the wrong questions:
- which platform should we buy
- which pipeline framework should we adopt
- which service makes us “do MLOps”
The better questions are much more operational:
- what exactly has to be reproducible in this project
- where do data and model ownership meet
- how do we evaluate change before and after release
- what part of the lifecycle is currently the least controlled
That is where the real MLOps work begins.
FAQ
Is MLOps only about model deployment?
No. Deployment is one part of it, but the term becomes misleading if we collapse everything into deployment. MLOps is broader because it deals with the lifecycle around data, model evolution, release operations and post-deployment evaluation.
Is MLOps just DevOps for machine learning?
Partly, but not fully. It inherits a lot from DevOps, because ML systems still need engineering discipline. The difference is that data behavior, experimentation and model drift add extra operational problems that classic software systems do not face in the same form.
When does a team actually need MLOps?
Earlier than most teams assume. The moment you expect an ML workflow to be repeatable, collaborative, versioned and maintainable beyond one person or one demo, you already need MLOps thinking, even if the implementation is still lightweight.
Final point
MLOps is not useful because it sounds modern. It is useful because machine learning systems create operational problems that do not disappear after the first successful experiment.
If we use the term, we should use it precisely.
MLOps is not a synonym for deployment. It is not a cloud product category. It is not a magical layer that appears after data science work is finished.
It is the discipline that keeps the whole ML project coherent once the work needs to be reproducible, collaborative, maintainable and real.